The communication system is inevitably affected by various interferences, so that the information received by the receiving end is inconsistent with the information sent by the sending end, that is, the information received by the receiving end generates an error code. In order to reduce the bit error rate of data communication line transmission, there are usually two methods to improve the data communication line transmission quality and error detection control. There are many methods of error detection control. This article discusses the method of parallel implementation of CRC-32 codec in the 10G Ethernet access system, and the Unfolding algorithm of the parallel CRC algorithm can realize the calculation of parallel CRC, but the resources used by the parallel circuit have increased to the original J times. The 8-bit parallel CRC algorithm, the parallel CRC-16 coding logic, and the parallel algorithm given by the parallel CRC algorithm in USB technology are all based on the formula recursion. When the parallel depth is small, the recursive algorithm is more suitable. When the parallel depth is large (10G Ethernet access system uses 64-bit parallel data channels), the recursion process is too cumbersome and lacks practicality. To this end, this paper proposes three algorithms, such as matrix method, substitution method and pipeline method, to solve the implementation problem of CRC algorithm in the case of deep parallel. Using the algorithm proposed in this paper, a logical expression for 64-bit parallel CRC calculation can be obtained and used in the design of a 10G Ethernet access system. Let M / (x) be the information polynomial and G (x) be the generator polynomial. The general CRC encoding method is: first shift the information code polynomial to the left by r bits, that is, M (x) · xr, and then perform modulo 2 division (M (x) xr) / G (x) = Q (x) + R (x) / G (x) (1) The resulting month (x) is the CRC check code. Take the CRC-32 encoding of binary code 0x9595H as an example: · CRC-32G generated multiple G (x) = x32 + x26 + x23 + x22 + x16 + x12 + xll + x10 + x8 + x7 + x5 + x4 + x2 + x + 1, converted to hex g = 0x104C01DB7H. Divide m by g (modulo 2 division), and the remainder 0x3738F30BH is 0x9595H CRC-32 code. The Matlab program to realize the basic CRC-32 encoding of 0x9595H is as follows: g (33: -1: 1) = [1,0 0 0 0 0 1 1 0 0,1 1 0 0 0 0 0 1,0 0 0 1 1 1 1 0 1,1 0 1 1 0 1 1 1]; a (48: -1: 1) = (1 0 0 1 0 1 0 1,1 0 0 1 0 1 0 1,0 0 0 0 0 0 0 0 0,0 0 0 0 0 0 0 0,0 0 0 0 0 0 0 0,0 0 0 0 0 0 0 0]; for i = 48: -1: 33, if a (i) = = 1 a (i: -1: i-32) = xor (a (i: -1: i-32), i (33: -1: 1)); end end crc = a (32: -1: 1) If you want to use the above CRC-32 program to calculate the basic CRC-32 codes of other sequences of length L, just change the upper bound of the array α and the initial value of i in the for loop to 32 + L, and use the sequence to replace the array. Just start the sequence "1001010110010101". The serial CRC encoder implemented with digital circuits is shown in Figure 1. Each rectangle in Fig. 1 represents a D flip-flop. The value range of gi is 1 or 0. When it is 1, it means the path, when it is 0, it means open circuit. When performing basic CRC-32 encoding, the initial state of each D flip-flop is 0, and the binary information code is serially input from the data terminal. After the information code is input, the value latched in the D flip-flop is the basic CRC-32 code of the information code. This circuit is suitable for the case where the information code length is any value. In some information systems, new regulations are added based on the basic CRC generation algorithm. For example, IEEE802.3 protocol stipulates that the FES (Frame Check Sequence) field of Ethernet is based on CRC-32, and the first 4 bytes of the information code are first inverted when encoding, and the destination address, source address, The length / type field, data field, and PAD field find the basic CRC-32 code and then invert the result. The final result is FCS. Another implementation method equivalent to the above process is to set the initial value of all D flip-flops in FIG. 1 to 1, so that the result does not have to be inverted. In order for the circuit designer to verify that its FCS code is correct, IEEE802.3 also gave a sample, namely: repeat the sequence 0xBED723476B8FB3145EFB3559H 126 times, and the final FCS value should be 0x94D254ACH. 10G Ethernet is a proposal made by the IEEE802.3ae working group. It maintains the frame structure of the previous Ethernet, but the line speed has reached the order of 10Gbps. In order to reduce the power consumption of the 10G Ethernet access system and meet the requirements of the chip processing technology, parallel data paths must be used. To calculate FCS, it is necessary to study the parallel CRC algorithm. The designed 10G Ethernet access system uses 64-bit parallel data paths, so this article mainly discusses the implementation method of 64-bit parallel CRC-32. This article introduces a total of three implementation methods, of which the matrix method and the substitution method are direct implementation methods based on combinatorial logic, and the third method is an implementation method based on pipeline. Note that the outputs of the 32 D flip-flops in Figure 1 are d31, d30, ..., d0 from right to left. The input terminal of the information symbol is i. Let D = [d0d1 ... d31] T represent the current state of the encoder, I = [i63i62 ... i0] represent the information symbol input of the 1st to 64th clocks, and the vector Dˊ = [d0ˊd1ˊ,… d31ˊ] T represent The next state of the encoder, D (64) represents the state of the CRC encoder after 64 clocks. Then design a 64-bit parallel CRC logic encoder, is to find the functional relationship D (64) = f (D, I). do '= d31 + i63 d1 '= d0 + d31 + i63 d2 '= d1 + d31 + i63 d3 '= d2 … d31 '= d30 Write in determinant, with D '= TD + Si63 among them: After 2 clocks, the state of the encoder is: D '' = TD '+ Si62 = T) TD + Si63) + Si62 = T2D + TSi63 + Si62 By analogy, there are: D (64) = T64D + T63Si63 + T62Si62 +… + TSi1 + Si0 (2) The semantics of the plus sign in all matrix operations and algebraic operations here is modulo 2 addition. in order to. To design a 64-bit parallel CRC circuit, the large-scale matrix multiplication T64, T63S, etc. in equation (2) must be calculated. 2 Substitution method The advantage of the matrix method is its intuitiveness. But it needs to do large-scale multiplication. The substitution method discussed below can achieve the same results as the matrix method. At the same time, large-scale matrix multiplication can be avoided. Suppose the initial state of the 8-bit parallel CRC-32 circuit is d31, d30, ..., d0, the input is i7, i6, ..., j0, and the output is z31, Z30, ..., z0. Using the matrix method described above, the combined logical expression of the 8-bit parallel CRC-32 encoder can be obtained. As shown in Table 1. which is: z31 = d23 + d29 + i5; z30 = d22 + d31 + i7 + d28 + i4 … z0 = d24 + d30 + i6 + i0 The following uses "+" for bitwise modulo 2 sum operation, and "{,}" for link operation. It is easy to derive the following algorithm from equation (1) of CRC: Algorithm 1: The CRC-32 of sequence N is known as A [31: 0], and the CRC-32 code of sequence B (= [b7, b6, ..., b0]) is Y [31: 0]. The CRC-32 of sequence A [31:24] is X [31: 0], then the CRC-32 code of extension sequence {N, B} is {Y [31:24] + X [31:24] + A [23:16], Y [23:16] + X [23:16] + A [15: 8] + A [7: 0], Y [7: 0] + X [7: 0]}. Corollary: The CRC-32 of sequence N is known as A [31: 0], and the CRC-32 of sequence A [31:24] is X [31: 0], then 0 is added to extend the CRC of sequence {N, O} The -32 code is {X [31:24] + A [23:16] + A [15: 8], X [15: 8] + A [7: 0], X [7: 0]}. Using the above algorithm to construct the APPEND module, its ports A and B respectively represent the CRC of the preamble sequence and the extended 8-bit sequence, then its output port Z is the CRC of the expanded sequence. Figure 2 uses the APPEND module to construct a 64-bit parallel CRC encoder with a cascade structure. The design of this cascaded encoder is relatively simple. The middle node: Z1 (n) = f (r, d [0: 7] n [31,0] Z2 (n) = f (Z1, d [8:15]) = f (f (r, d [0: 7]), d {8:15]) … (3) 3 Pipelining The matrix method and the substitution method are essentially methods for designing direct parallel encoding circuits, and the final effect of the two is the same. The control logic of the CRC coding circuit implemented directly in parallel is relatively simple, but it requires complex combinational logic operations. In order to perform parallel CRC encoding at a higher frequency, the encoding logic can be further simplified by the pipeline method. The price paid is that the processing of the entire frame is delayed by 8 clock cycles. Figure 4 shows the pipeline implementation of CRC encoding. The 64 bits input in parallel are divided into 7 bytes, which are respectively denoted by D0, D1, ..., D7. The P module (P0 ~ P7) calculates the CRC of a sequence of the form "Di, O, O, O, O, O, O, O, O, Di", where Diˊ is the last input at the Di position. Diˊ's CRC code is input from port R [31: 0], Di is input from port D [7: 0], and the result is output from Z [31: 0] port. The input of the C module (C1 ~ C7) is "D0, O, O, O, O, O, O, O, D0 'and" D1ˊ, O, O, O, O, O, O, O, D1 " CRC (input from ports R1 and R2, respectively), the output is "D0ˊ, D1ˊ, O, O, O, O, O, O, D0, D1" CRC. When finding the logical expression of P, repeatedly apply the inference of Algorithm 1 , You can find the "Diˊ, O, O, O, O, O, O, Di" CRC code, and then apply Algorithm 1, you can find "Diˊ, O, O, O, O, O, O, O , Di "CRC code. Direct application of algorithm 1 can find the logical expression of C module. The length of the XOR operation between P module and C module is much shorter than that of ENC8 module in direct parallel CRC circuit, so it is more conducive to high-speed circuits Medium application. The required interface rate of 10G Ethernet access system is up to 10Gbps. From the perspective of reducing system power consumption and chip manufacturing costs, it is expected that the interface can work below 200MHz. Although the parallel design can reduce the system clock frequency, it also increases the design difficulty from the following two aspects. First of all, the higher the parallelism of the data path, the more complicated it is to control. The system uses an 8-byte parallel data path, and the Ethernet frame sent may end at any position in the 8 parallel bytes. The design of the control logic must consider all these possibilities and make corresponding processing one by one. Secondly, the design of the CRC encoder and scrambler in the system must use parallel algorithms. In order to meet the requirements of IEEE802.3 protocol for CRC encoding of Ethernet frames, the actual codec module also needs to be able to perform the inverse operation of any number of bytes on the input and output signals. Considering the complexity of the 10G access system, the function of this module should be highly integrated in order to operate it with a macro signal port. When checking the received Ethernet frame, it is not necessary to calculate the CRC code of the sequence excluding the FCS field (the result is inverted) before comparing with the FCS field. When the encoding is correct and there are no errors, the result of CRC encoding that does not invert the result of the entire Ethernet frame (including the FCS field) should be the sequence 0xC704DD7BH. With this discriminating method, there is no need to stop calculating the CRC code before the end of the frame, so the circuit design can be greatly simplified. 5 Implementation of CRC encoder The hardware implementation of various algorithms proposed in this paper has been verified by FPGA and applied to specific chips. The XC2V1000 in Xilinx's Virtex2 series FPGA was used to simulate the CRC encoder and decoder designed by the above substitution method and pipeline method, respectively, and the correctness of the design method was verified. After comprehensively considering the logic complexity, the occupied chip area and the process requirements, the CRC encoder and decoder designed by the substitution method are finally adopted in the designed 10G Ethernet access chip. A parallel CRC encoder is required in the 10G Ethernet access system. This paper proposes a direct implementation based on combinational logic and an implementation method based on pipeline. The methods of direct realization are divided into two kinds of matrix method and substitution method. After specific derivation, it is found that the directly implemented encoder can meet the delay requirement, so it is adopted by this system. The pipeline-based design can be used at higher speeds because of its smaller delay. The three parallel design methods proposed in this paper have passed hardware verification. These design ideas are also applicable to the design of other linear shift registers, such as scramblers. Detachable Earbuds,Earphones With Detachable Cable,Earbuds With Detachable Cable,Earbuds With Replaceable Cable Dongguang Vowsound Electronics Co., Ltd. , https://www.vowsound.com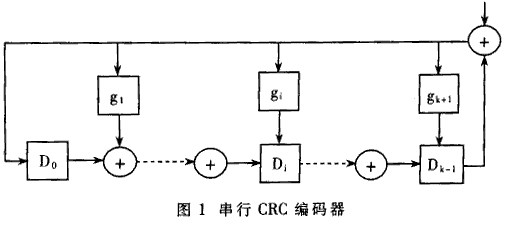
· Shift the information code to the left by 32 bits to become 0x959500000000H, and record it as m. 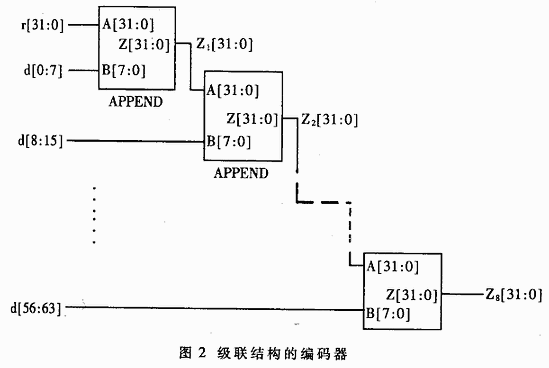
1 Matrix method 
Table 1 8-bit row CRC logic table z0 d24, d30, i6, i0 z1 d25, d31, i7, i1, d24, d30, i6, i0 z2 d26, i2, d25, d31, i7, i1, d24, d30, i6, i0 z3 d27, i3, d26, i2, d25, d31, i7, i1 z4 d28, i4, d27, i3, d26, i2, d24, d30, i6, i0 z5 d29, i5, d28, i4, d27, i3, d25, d31, i7, i1, d24, d30, i6, i0 z6 d30, i6, d29, i5, d28, i4, d26, i2, d25, d31, i7, i1 z7 d31, i7, d29, i5, d27, i3, d26, i2, d24, i0 z8 d0, d28, i4, d27, i3, d25, i1, d24, i0 z9 d1, d29, i5, d28, i4, d26, i2, d25, i1 z10 d2, d29, i5, d27, i3, d26, i2, d24, i0 z11 d3, d28, i4, d27, i3, d25, i1, d24, i0 z12 d4, d29, i5, d28, i4, d26, i2, d25, i1, d24, d30, i6, i0 z13 d5, d30, i6, d29, i5, d27, i3, d26, i2, d25, d31, i7, i1 z14 d6, d31, i7, d30, i6, d28, i4, d27, i3, d26, i2 z15 d7, d31, i7, d29, i5, d28, i4, d27, i3 z16 d8, d29, i5, d28, i4, d24, i0 z17 d9, d30, i6, d29, i5, d25, i1 z18 d10, d31, i7, d30, i6, d26, i2 z19 d11, d31, i7, d27, i3 z20 d12, d28, i4 z21 d13, d29, i5 z22 d14, d24, i0 z23 d15, d25, i1, d24, d30, i6, i0 z24 d16, d26, i2, d25, d31, i7, i1 z25 d17, d27, i3, d26, i2 z26 d18, d28, i4, d27, i3, d24, d30, i6, i0 z27 d19, d27, i5, d28, i4, d25, d31, i7, i1 z28 d20, d30, i6, d29, i5, d26, i2 z29 d21, d31, i7, d30, i6, d27, i3 z30 d22, d31, i7, d28, i4 z31 d23, d29, i5 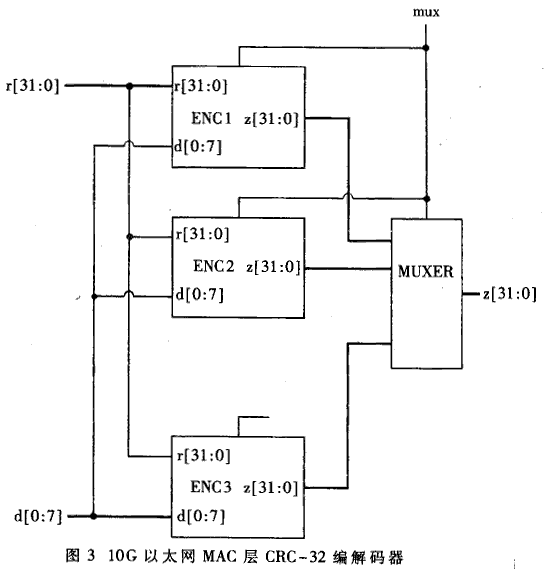
Obviously (3) can be further simplified. Redundant logic makes this cascade structure occupy a large chip area, and can only be used in low-speed occasions. By further simplifying (3), the simplest XOR expression of Z2 can be obtained. Similarly, the expressions of Z3 ... Z8 can be obtained. Zl, Z2, ..., Z8 correspond to 8-bit, 16-bit, ..., 64-bit parallel CRC operation expressions. Specific expressions are not given here due to space limitations. The longest XOR expression in Z8 has 52 items to participate in the calculation. If you use a 4-XOR gate, you only need to use three levels, which can be completed within the first-level transmission delay time of the general CMOS process. When used in an Ethernet access system, because the Ethernet frame does not necessarily end at a 64-bit boundary, the encoder should have the ability to calculate 8, 16, 24, ..., 64-bit parallel encoding at the same time. The specific circuit is shown in Figure 3. Because 64-bit parallel encoding is generally used in large numbers, the mux enable signal usually disables the other 7 encoding modules to reduce power consumption. At the end of the frame, use these 7 modules to encode the remaining bytes according to the specific situation. 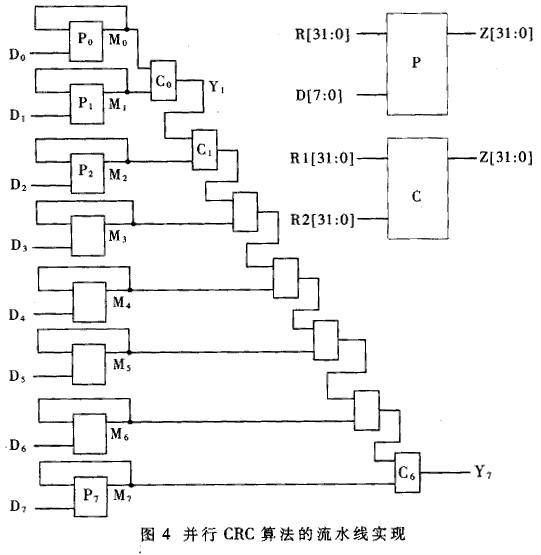
4 Design of CRC codec in 10G Ethernet access system
April 20, 2020